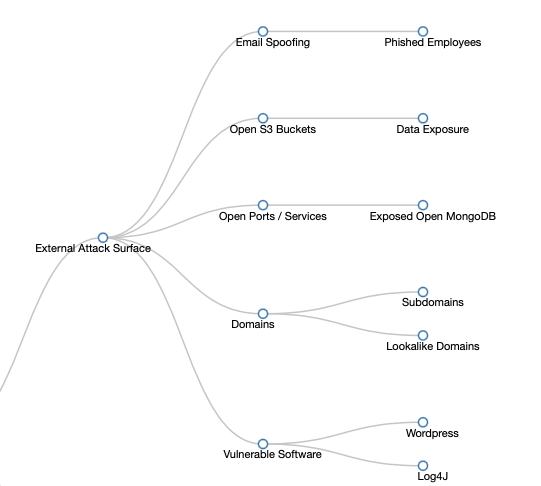
Do you remember Maslow's Hierarchy of needs? How humans need food and water before they can start thinking about self actualization? This post talks about the first level in a theoretical security hierarchy of needs.
We use cookies to ensure that we give you the best experience on our website. By clicking "ok" you are consenting to our use of cookies.OkNoPrivacy policy