Services
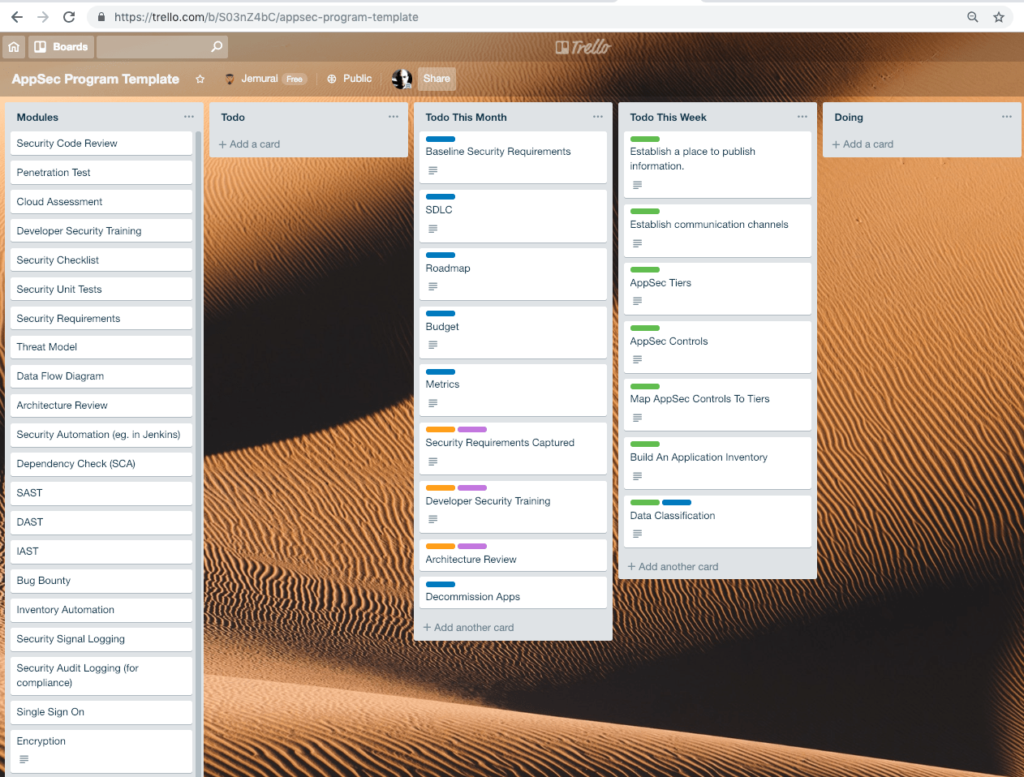
Last week I wrote about application security programs What is a program and why do we need it? After writing that post, I realized it might be helpful to go a bunch deeper and share some of the processes we use when we engage with clients to help them build AppSec programs. To make it more real, I put together a Trello board and asked for feedback on it. Many of the cards on the board itself have additional detail embedded in them as well, but it seemed like a good idea to step back and explain it. This post introduces that board and talks through the reasoning behind it.
It is a long read. Sorry … not sorry.
The first thing you should notice when we drop the Trello board into place is that there is nothing in the DOING column. I happen to like using very consistent naming with Trello columns because it makes it easier to search and find tasks across boards. But the point here is, when we start, we haven’t done anything yet, and we are being a little careful about our assumptions about what we are going to do. We don’t want to give the impression that we’re about to start a one size fits all program.
As you would expect, when we’re done with something we want to show that clearly and take credit for it by moving it to the Done column, which I will not discuss in detail here.
The Todo This Week column includes the very first things we’re going to do as we stop to build the program. Sometimes we call this a Discovery phase of a project. Now, we’re assuming that we have a clean point in time to start. Even if an organization has started programs in the past or has existing processes, it is a good practice to stop and understand those. Often, those relics of past efforts represent really important pitfalls we want to avoid. So even if you drop into the middle of a running program, it will probably help to do these initial discovery activities.
If a security program grows in the forest and no-one ever sees it, did the security program grow? (Did it matter?)
We typically find GitHub projects or Confluence or Sharepoint places to share information. Google Docs or One Drive areas can work, but the information needs to be digestible and accessible, so we recommend linking it and being very conscious of what it looks like to a new visitor navigating.
This is a good point to stop in time and remind ourselves that what we write isn’t writer focused but rather reader focused. It simply doesn’t matter what we have captured in writing if we can’t make it easy for someone to read. This post may be a long read, but when we’re communicating with other parts of the organization, we need to be careful to be civil and direct.
We need to put in extra time to make our communication work.
In addition to where we capture information, we also need to make sure that we help the application security team to be accessible and available. It is inevitable that someone will want to get feedback or get a PR approved or have requirements reviewed or understand how to follow a process and if the AppSec team isn’t able to even engage to answer the question, the game is over.
If your organization sounds like this and the AppSec team can’t handle ad hoc questions from development teams, you should just assume that App Security isn’t happening.
We generally recommend several channels:
The important thing here is that these channels shouldn’t just be what you want them to be in a going in position. These should reflect the best approach to reach the developers across all of the teams.
We always use 3 tiers for applications. It is possible there could be a reason to use more or less, but this has always worked for us.
The singular purpose of the tiers is to break down work and prioritize. It is important for us to be dispassionate about what goes in what tier. Now that we have a “Place To Publish Information” we now publish the Tiers as a stand along page to keep it as simple as possible.
The purpose of capturing the AppSec Controls is to help us know what the organization is capable of. Some orgs have lots of resources actively working with AppSec. Others have very few. Some have tools. Others rely on all open source. The written list should include all of the tools and processes we’ll talk about.
We may have recommendations based on the details at that client but we’re going to start by capturing what they think they can actually do right now. This becomes a catalog of controls we can apply. You could almost think of it as a “Service Catalog” of services that the AppSec team can offer to the organization either as direct services or as managed self service activities.
As a preview, these controls may all map to the Modules you see at the far left of the Trello board. That column reflects the activities we could do. The written list here captures what our current repertoire is.
Many organizations we work with know they have sensitive data at an executive or legal level but that information doesn’t get carried through the organization or used actively in building a program.
We typically classify data into 3 tiers just like we did apps and we develop explicit examples of the fields which should get classified in different ways.
In the initial week, we can paint with a bit of a broad brush and just try to understand if there is regulated or very important data involved. Again, most companies we work with vaguely know that they have PCI data or PHI or PII or intellectual property, etc. They just don’t know how to handle that.
Tier | Type | Example |
|---|---|---|
| 1 | Secret | PHI, PII, PCI, FERPAFERPA (Family Educational Rights and Privacy Act) is a US federal law that protects the privacy of student education records. It applies to all educational institutions that receive funding from the US Department of Education. FERPA gives students and their parents certain rights, including the right to inspect and review their education records, the right to request that records be corrected, and the right to control the disclosure of personally identifiable information in their records., Passwords, Keys, etc. |
| 2 | Internal | Budgets |
| 3 | Public | Tech stack |
Developing a true Data Classification is something that takes longer than we can do in a quick first week of work. That effort may require lawyers, executive approvals, etc. We should absolutely circle back to that and identify specific fields and how they need to be handled (encrypted, etc.) at a later time. For now, in the first week kickoff, we just need to know where the standards are going to tie our hands as far as the next activity.
This is a part of the project that sounds simple but is actually extremely difficult both from a technical and political perspective. The goal of this activity is to capture in writing what AppSec Controls the stakeholders want to have applied at each AppSec Tier. For example, for a tools and pen testing focused organization it might look like this:
Tier | Controls |
|---|---|
| 1 | Penetration TestingPenetration testing, also known as pen testing, is a security assessment method that simulates a real-world attack to identify vulnerabilities in a system, application, or network. Penetration tests are conducted by ethical hackers who attempt to exploit weaknesses in a system's security defenses using a variety of tools and techniques. The goal of a penetration test is to identify vulnerabilities and provide recommendations for remediation before they can be exploited by malicious actors., SAST, DAST, Dependency Checking (SCA) |
| 2 | SAST, DAST |
| 3 | SAST |
For each AppSec Control we have in our quiver of arrows to apply, we need to figure out if we’re going to apply it at all and if so at which Tier.
Obviously, the costs go up as we do more. Ideally we want Tier 1 to be a limited number of applications. That’s the whole point of Tiering.
Interestingly, Data Classification may force our hand here. For example, there may be 3 applications that handle PCI data. PCI is quite detailed about the controls we need to have in place for systems handling credit card data. So we can’t allow the mapping of controls to tiers to violate our basic regulatory responsibilities.
The other really important point here is that this is inherently an educational discussion with stakeholders. They probably don’t know a lot about the regulations. They probably don’t know a lot about the security tools. Stakeholders have the ultimate say about what security activities we undertake and how secure the environment really needs to be. At least if they really control the budget and spending they do.
Ultimately, we want to bring the security team, the development team and the business to the table in agreement about what controls are being applied to what tiers.
Notice that we didn’t yet say which apps are where. Doing this exercise in the abstract is really important because it forces the team to think about the details in principle.
It is worth briefly mentioning that the best security tools may not be the ones that are mandated by regulations because of the lag between when regulations get written and enforced.
Of course, just like the Tiers, Classification and Controls, this needs to get captured and written down in the place we’re using to publish information.
Now that we have some of the ground rules laid out, we can start to see how big a problem we have. We do this by collecting a list of the applications we have.
Sometimes this is just a google or excel sheet. Other times it is a service inventory service. Ideally it is something that can be automated, but to start out it won’t be.
Note that people often ask about the right level of granularity for the inventory. I always say the repo level. Even if a bunch of micro services look like the same application from the front end, they may handle different data and need to be subject to different Tiers.
Once we have the inventory, it might start to look like this:
Then add columns for the controls you are using, eg.:
Generally, we like to use dates of the last activity in the columns. In the future that will allow us to identify when we next need to do certain activities.
This is a very brief intro to inventories, which I’ve talked about a few times before. Let’s assume that now you have a list of 4,10,50,250 or 1200 repos in your inventory. Given that you know what needs to be done for each repo, you know how screwed you are.
Stepping back for a moment, what we just did was build a positive or constructive model for how our AppSec program will work. The budget and roadmaps we’re going to talk about soon will be derived from the ground up work we’ve done thus far.
To put it another way, we didn’t build this program as a modification of something else or based on some theoretical perfect scenario. We collaborated with stakeholders to agree to terms of engagement and now the model flows out of what we have.
Up to this point, we’ve been focusing on things we can usually do in the first week or two at most clients. This next set of items represent the items we would tee up to tackle in the following weeks after that initial discovery.
In every engagement with engineering teams, we try to work toward a set of Baseline Security Requirements that everyone is aware of. These go beyond the general: Don’t introduce SQL InjectionInjection is a type of cyber attack where an attacker exploits vulnerabilities in an application or system to inject malicious code or commands. Injection attacks are often carried out by inserting code or commands into input fields or parameters that are passed to an application or database. or XSS. These are more like, use XYZ for Identity. Use DEF for audit logging. Encrypt data with keys from LMN. We treat these requirements like non functional requirements. They are things that always need to be true about any system we are building. A common NFR might be: Support 10,000 requests per minute. That doesn’t belong on a story, it should be true across stories or tasks.
These baseline requirements are important to capture and document. They also form the basis of strong repeated training content. We usually drop in with a template that we can navigate with a client to get this bootstrapped.
Some companies we work with have no SDLC. Others have 29. While we know that developers sometimes avoid process, we need to have some base agreed upon process. We have a template for this but usually end up capturing and making minor modifications to client’s written SDLC’s.
The things we care a lot about are that code is tracked, builds are done in a repeatable way, stakeholders can see what is being done and why, and security is included in the estimation process.
This could be a whole topic and it is a place where having written a lot of code on big teams using different variations of Agile processes really helps Jemurai. We can typically find common ground with developers and adapt to the processes being used. This can be harder or feel out of control for folks accustomed to more control.
A roadmap is a document that describes how we get from point A to point B. It is inherently customer specific. It might be a spreadsheet like a budget with months across the top and activities in the Cells. It might be drawn like a timeline. Depending on the size and complexity of the organization, it might be possible to visualize the roadmap in one go. In most we see, it is not. We find that you’ll want to filter roadmap activities by tools, tasks, dates, etc.
The bottom line is that our inventory plus control mappings has already told us what we need to do. What we need to do here is plan out how we’re going to do it. Often projects fall apart at this stage because there is too much work to possibly do with the resources available.
We recommend making milestones, setting intermediate goals and having several threads of work progressing at any given time. From our engineering backgrounds we know that if you have very big lifts (hard tasks with lots of risk) that we don’t want to save them for the end.
The roadmap is also a place to think about which things are going to be done in house and which need to be outsourced.
Sometimes we combine the roadmap and budget. The one implies the other, but it can be most useful to think about them separately.
If you don’t know how to read and write a budget, it is a skill we strongly recommend developing. The budget is where the rubber meets the road. The dollars we spend have some outcome. They are always limited. We need to spend wisely. We also need to be able to model different scenarios with a budget. We want to be able to say “What if?” for a variety of questions. What if we pen test Tier 1 and Tier 2 applications? What if we only code review Tier 1 and not Tier 2 applications? How does that effect spend?
A budget typically looks something like this – with columns for each month and rows for each activity or type of activity. The dollars add vertically to show what is being spent each month and horizontally to show how much per activity.
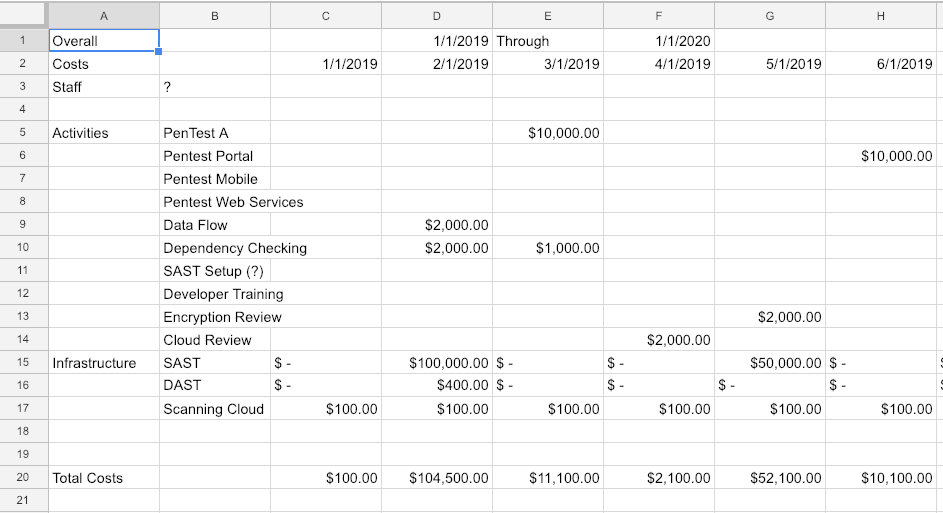
Ultimately, without budget responsibility, you can’t have responsibility for outcomes. Some managers keep the budget close. Others give their team wide freedom to implement a program the way they want. It isn’t reasonable to go from 0 – 60 (no budget – budget responsibility) in a month or two, but it is reasonable and important to both develop this skill and seek out those who have it and are doing it now.
If you budget is last year plus 10% across the board, you are doing it wrong. That’s the whole point of the inventory and activity mapping: to build a bottoms up budget based on what you should be doing.
I could talk all day about metrics too. Let’s start by discarding security effectiveness metrics. Yes, you should do them. Yes, you should seek out the best data and answers that you can. When you replan, you can use those metrics to decide about new activity mappings – meaning you can use effectiveness metrics to prioritize one type of control over another. My point is, these types of metrics are a little different from what we’re talking about here.
Step back and think about what your boss will care about from a metrics perspective:
A maturity model is fairly easily derivable from the inventory. Ultimately, metrics are what drive the perceived value of the program up the management chain.
We typically talk with clients before ever pulling modules into delivery but in this case, we have a few that we think are essential and we want to include for reference.
It is very difficult to make concrete progress with security without identifying requirements. We already talked about the Baseline Security Requirements. Those are the ones that should always be there. This module is about finding the right place and process to make sure that there is a discussion about security while requirements are captured. This means that there are acceptance criteria on stories or some variant of that which explicitly calls out security requirements for developers.
We treat this as critically important because without this, we can’t estimate for security as developers and that means we’re going to be putting ourselves under pressure for delivering it right out of the gate!
Going along with having a strong program, developers need to be educated about not just application security concepts in general, but also the program we are developing. We find that including developer education in our core program development helps to align interests later.
Often, applications are designed in such a way that they expect certain foundational things to be true and the security depends on things that are outside of developers direct control. We like to do architecture review early (and often, with ADR to ensure that the overall system doesn’t end up with expectations it cannot meet.
Architecture review often identifies significant shifts in technology or libraries and it is usually better to catch those as early as possible so that less code is built on top of the questioned building blocks.
One of the easiest ways to reduce exposure is to take old applications that are hard to maintain and even keep updated offline. This has a cost, but not doing so also has a cost. As we build a program, we absolutely want to identify easy wins where we can decommission an application and reduce risk. We do this as early as possible without putting it before the core scoping and program building activities. We could even have a tier for TBD (to be decommissioned). That can be dangerous too because often those just languish and never are decommissioned.
We won’t cover the modules in detail here but each module represents a unit of work that we can plug into the plan. Some we do once, others we need to do per application. There is a fair amount of complexity as it comes to actually breaking off and implementing the modules – but the idea should be clear even without that. For example, we can define the work to set up security automation in Jenkins then do that repeatably for the base scenarios.
We use Modules both to capture the work for ourselves so that we can deliver on these items repeatably but also to emphasize how the plan is assembled from these chunks of work.
It may be tempting to apply vendor logic and use tools everywhere and anywhere that you can. Of course, good tools are good. We encourage anyone that hung on this long reading to step back and think about the number of FIXES that they are getting out of their program. A program should not be tool focused, it should be a balance. Any tool that wants to own your whole program may be also trying to make it difficult for you to switch tools.
We strongly encourage AppSec teams to leverage OSS to do automation and build the program and then plug in commercial tools as appropriate where they can be proven to help.
We would also note that many of the activities that will have the best results with developers are not tools related activities. Writing security requirements and security unit tests for example is a very “low tech” way to address security concerns. The benefit of these activities however is that developers (and future developers) can understand the security controls that are being mandated and checked.


